DBSCAN
DBSCAN is short for Density-based spatial clustering of applications with noise. Given a set of points in some space, it groups together points that are closely packed together (points with many nearby neighbors), marking as outliers points that lie alone in low-density regions (whose nearest neighbors are too far away). DBSCAN is one of the most common, and most commonly cited, clustering algorithms.
Algorithm
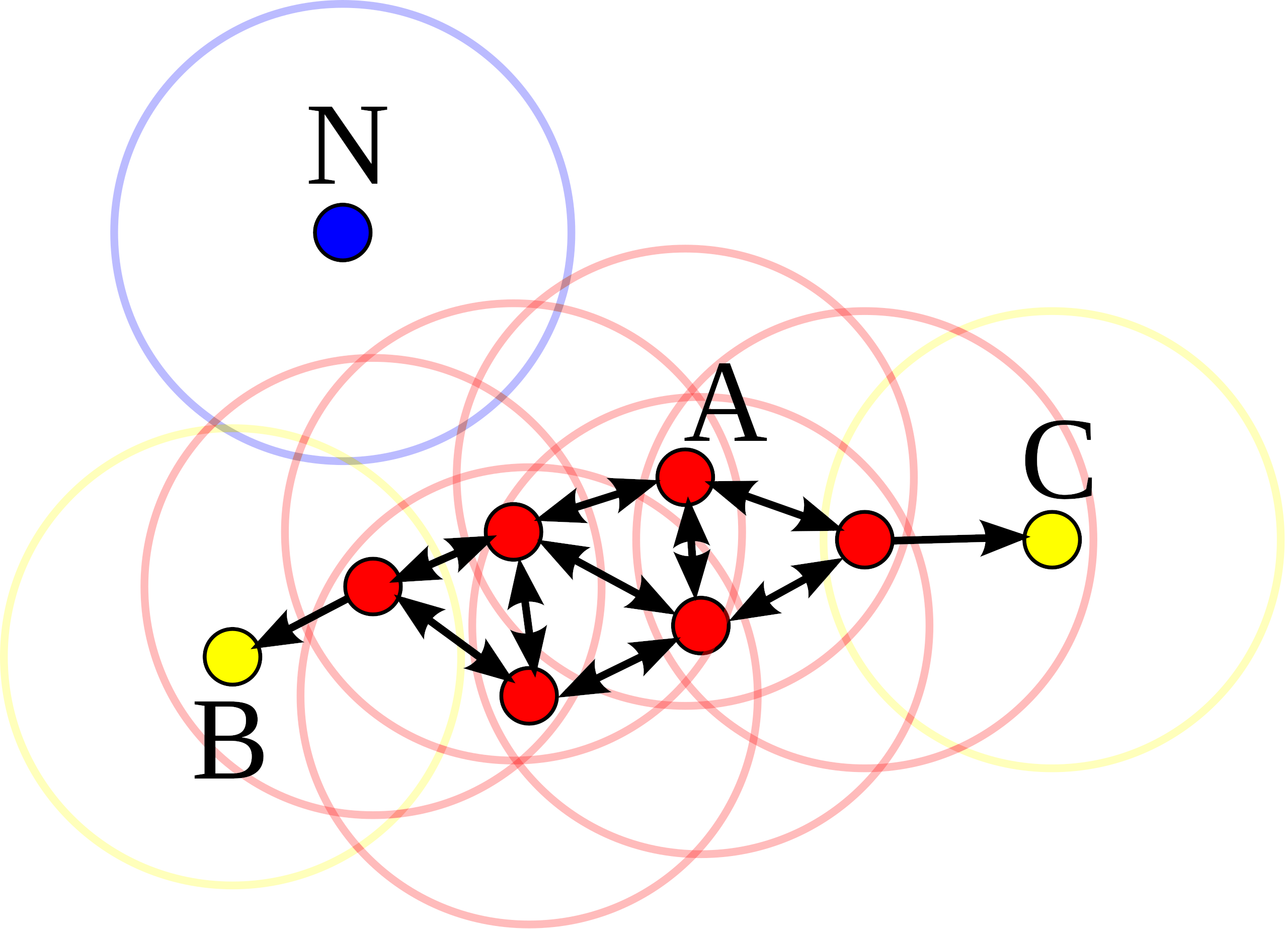
Consider a set of points in some space to be clustered. Let
- A point
- A point
- A point
- All points not reachable from any other point are outliers or noise points.
Now if
Illustration
DBSCAN can find non-linearly separable clusters. The following dataset cannot be adequately clustered with [[K-Means]] or Gaussian Mixture EM clustering.

Pros
- DBSCAN does not require one to specify the number of clusters in the data a priori, as opposed to K-Means.
- DBSCAN can find arbitrarily-shaped clusters. It can even find a cluster completely surrounded by (but not connected to) a different cluster. Due to the MinPts parameter, the so-called single-link effect (different clusters being connected by a thin line of points) is reduced.
- DBSCAN has a notion of noise, and is robust to outliers.
- DBSCAN requires just two parameters and is mostly insensitive to the ordering of the points in the database.
- The parameters minPts and
Cons
- DBSCAN is not entirely deterministic: border points that are reachable from more than one cluster can be part of either cluster, depending on the order the data are processed. For most data sets and domains, this situation does not arise often and has little impact on the clustering result.
- The quality of DBSCAN depends on the choice of a distance. The most common distance metric used is Euclidean distance. Especially for high-dimensional data, this metric can be rendered almost useless due to the so-called "Curse of dimensionality", making it difficult to find an appropriate value for
- DBSCAN cannot cluster data sets well with large differences in densities, since the minPts-
- If the data and scale are not well understood, choosing a meaningful distance threshold